


 ¿MEJOR MOTHER GAMA MEDIA…
¿MEJOR MOTHER GAMA MEDIA…
 UGREEN POWER BANK
UGREEN POWER BANK 


 ¿REALMENTE RINDE?
¿REALMENTE RINDE?











 con una vibrante pantalla OLED de 7 pulgadas, que se lanzará el 8 de octubre")











 ARGENTINA…
ARGENTINA…
 NO COMPRES EN ESTA TIENDA DE HARDWARE
NO COMPRES EN ESTA TIENDA DE HARDWARE 
 YOUTUBE HW REWIND
YOUTUBE HW REWIND  2023")



AMD lanzará su tercera generación de procesadores de escritorio Ryzen 3000 Socket AM4 en 2019, con un producto previsto para mediados de año, probablemente al margen de Computex 2019. AMD mantiene su promesa de hacer que estos chips sean compatibles con las placas base Socket AM4 existentes. A tal efecto, los proveedores de placas base, como ASUS y MSI, comenzaron a implementar actualizaciones de BIOS con el microcódigo AGESA-Combo 0.0.7.x, que agrega soporte inicial para que la plataforma ejecute y valide muestras de ingeniería de los próximos chips “Zen 2”.
En el CES 2019, AMD presentó más detalles técnicos y un prototipo de un procesador Ryzen socket AM4 de tercera generación. La compañía confirmó que implementará un diseño de módulo de chip múltiple (MCM) incluso para su procesador de escritorio convencional, en el que utilizará uno o dos chips de núcleo de CPU “Zen 2” de 7 nm, que hablan a un I / 14 nm de 14 nm. O controlador muere sobre Infinity Fabric. Los dos componentes más importantes de la matriz IO son el complejo raíz PCI-Express y el importante controlador de memoria DDR4 de doble canal. Le traemos detalles nunca antes informados de este controlador de memoria.
AMD tiene dos grandes razones para tomar la ruta MCM incluso para su plataforma de escritorio convencional. La primera es que les permite mezclar y combinar tecnologías de producción de silicio. Los contadores de frijoles de AMD consideran que es más económico construir solo esos componentes en un proceso de producción reducido de 7 nanómetros, que puede beneficiarse de la reducción; es decir, los núcleos de la CPU. Otros componentes, como el controlador de memoria, pueden seguir construyendo sobre las tecnologías existentes de 14 nm, que ahora son muy maduras (= rentables). AMD también está compitiendo con otras compañías por su participación en la asignación de 7 nanómetros en TSMC.
El troquel de controlador de E / S de 14 nm podría, en teoría, provenir de GlobalFoundries para cumplir con el acuerdo de suministro de obleas. La segunda gran razón es la economía de la reducción de escala. Se espera que AMD aumente los recuentos de núcleos de CPU más allá de 8 y la acumulación de 12 a 16 núcleos en una sola losa de 7 nm hará que crear SKU más baratos al deshabilitar los núcleos sea costoso, ya que AMD no siempre cosecha troqueles con núcleos defectuosos. Estos SKU de gama media se venden en volúmenes más altos, y más allá de un punto, AMD se ve obligado a desactivar los núcleos perfectamente funcionales. Tiene más sentido construir chiplets de 8 o 6 núcleos, y en SKU con 8 o menos núcleos, implementar físicamente solo un chiplet. De esta manera, AMD está maximizando su utilización de preciosas obleas de 7 nm.
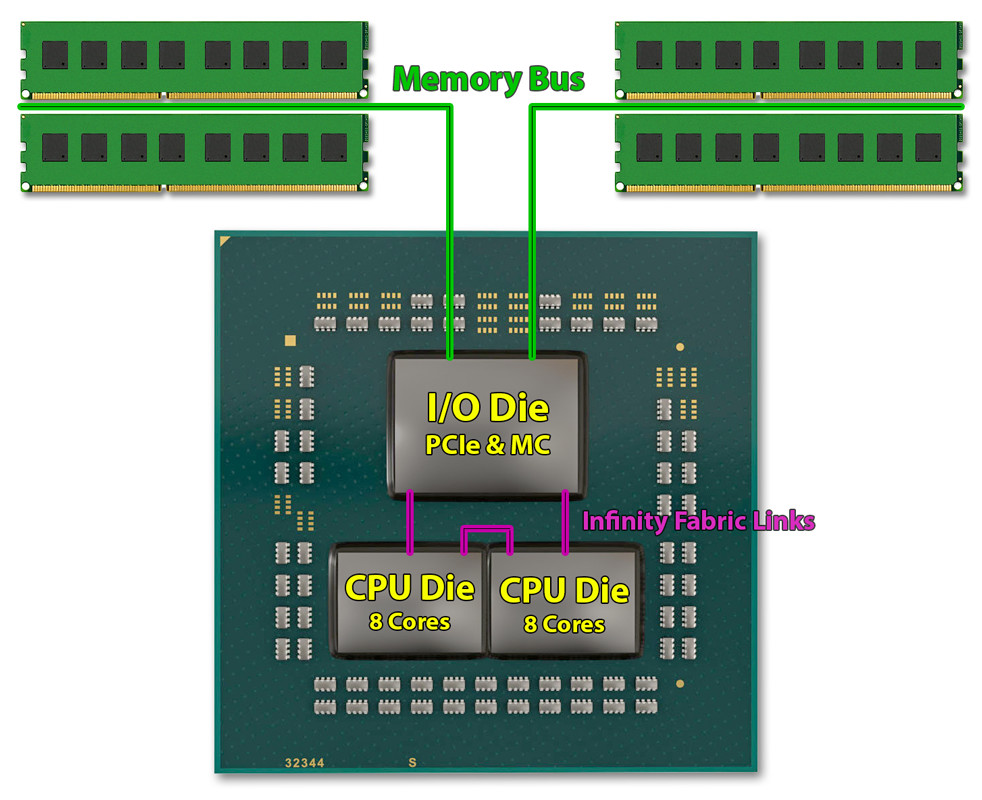
La desventaja de este enfoque es que el controlador de memoria ya no está físicamente integrado con los núcleos del procesador. El procesador Ryzen de tercera generación (y todas las demás CPU Zen 2) tienen un controlador de memoria “discreto integrado”. El controlador de memoria está ubicado físicamente dentro del procesador, pero no está en la misma pieza de silicio que los núcleos de la CPU. AMD no es el primero en crear un artilugio así. El procesador Core “Clarkdale” de la primera generación de Intel tomó una ruta similar, con núcleos de CPU en un dado de 32 nm, y el controlador de memoria más una GPU integrada en un dado de 45 nm por separado.
Intel usó su Interconexión de ruta rápida (QPI), que era de vanguardia en ese momento. AMD está aprovechando Infinity Fabric, su última interconexión escalable de gran ancho de banda que se implementa en gran medida en las líneas de productos “Zen” y “Vega”. Hemos aprendido que con “Matisse”, AMD presentará una nueva versión de Infinity Fabric que ofrece el doble de ancho de banda en comparación con la primera generación, o hasta 100 GB / s. AMD necesita esto porque un solo troquel de controlador de E / S ahora debe interactuar con hasta dos CPU de 8 núcleos, y hasta 64 núcleos en su línea de servidor “EPYC” SKU.
Nuestro residente Ryzen Memory Guru Yuri “1usmus” Bubliy echó un vistazo muy de cerca a una de estas actualizaciones de BIOS con AGESA 0.0.7.x y encontró varios nuevos controles y opciones que serán exclusivos de “Matisse”, y posiblemente la próxima generación Procesadores Ryzen Threadripper. AMD ha cambiado el título de la sección CBS de “Opciones comunes de Zen” a “Opciones comunes de Valhalla”. Hemos visto este nombre en clave en la web bastante en los últimos días, asociado con “Zen 2”. Hemos aprendido que “Valhalla” podría ser el nombre en código de la plataforma que consiste en un procesador AM4 Ryzen “Matisse” de tercera generación y su placa madre AMD 500 complementaria, especialmente el sucesor de X470 que AMD está desarrollando internamente. a diferencia de la fuente de ASMedia.
Cuando se realiza un overclocking serio de memoria, puede ocurrir que Infinity Fabric no pueda manejar el aumento de la velocidad de la memoria. Recuerde, Infinity Fabric se ejecuta en una frecuencia sincronizada con la memoria. Por ejemplo, con la memoria DDR-3200 (que funciona a 1600 MHz), Infinity Fabric operará a 1600 MHz. Este es el valor predeterminado de Zen, Zen + y también Zen 2. A diferencia de las generaciones anteriores, el nuevo BIOS ofrece opciones UCLK para “Auto”, “UCLK == MEMCLK” y “UCLK == MEMCLK / 2”. La última opción es nueva y será útil cuando haga overclocking en su memoria, para lograr estabilidad, pero a costa de un poco de ancho de banda Infinity Fabric.
Precision Boost Overdrive recibirá un control más preciso en el nivel del BIOS, y AMD está realizando cambios significativos en esta función para que la configuración de refuerzo sea más flexible y mejore el algoritmo. Los primeros usuarios de AGESA Combo 0.0.7.x en las placas base de chipsets de la serie AMD 400 notaron que PBO se rompió o se convirtió en un buggy en sus máquinas. Esto se debe a la mala integración del nuevo algoritmo PBO con el existente compatible con “Pinnacle Ridge”. AMD también implementó “Core Watchdog”, una función que restablece el sistema en caso de que la dirección o los errores de datos desestabilicen la máquina.
El procesador “Matisse” también proporcionará a los usuarios un control más preciso sobre los núcleos activos. Dado que el paquete AM4 tiene dos chips de 8 núcleos, tendrá la opción de deshabilitar un chiplet completo, o ajustar el conteo de núcleos en decrementos de 2, ya que cada chiplet de 8 núcleos consta de dos CCX de 4 núcleos (complejos de cómputo) , al igual que los diseños existentes de AMD. En el nivel de chiplet, puede reducir los recuentos de núcleos de 4 + 4 a 3 + 3, 2 + 2 y 1 + 1, pero nunca de forma asimétrica, como 4 + 0 (que fue posible en la primera generación de Zen). AMD está sincronizando los recuentos de núcleos CCX para una utilización óptima de la memoria caché L3 y el acceso a la memoria. Para el Threadripper de 64 núcleos que tiene ocho chiplets de 8 núcleos, podrás desactivar los chiplets siempre que tengas al menos dos chiplets habilitados.
CAKE, o “extensor de socket AMD coherente” recibió una configuración adicional, a saber, “CAKE CRC performance Bounds”. AMD está implementando IFOP (Infinity Fabric On Package,) o la versión sin zócalo de IF, en tres lugares en el MCM “Matisse”. La matriz del controlador de E / S tiene enlaces IFOP de 100 GB / s a cada uno de los dos chiplets de 8 núcleos, y otro enlace IFOP de 100 GB / s conecta los dos chiplets entre sí. Para las implementaciones de “zen 2” de varios zócalos, AMD proporcionará controles de nodo NUMA, a saber “nodos NUMA por zócalo”, con opciones que incluyen “NPS0”, “NPS1”, “NPS2”, “NPS4” y “Auto”.
Con “Zen 2”, AMD presenta un par de nuevas funciones principales de nivel DCT. El primero se llama “DRAM Map Inversion”, con opciones que incluyen “Disabled”, “Enabled” y “Auto”. La descripción del proveedor de la placa base de esta opción es como “Utilizar correctamente el paralelismo dentro de un canal y un dispositivo DRAM. Los bits que se voltean con más frecuencia deben usarse para asignar recursos de mayor paralelismo dentro del sistema”. Otro es “DRAM Post Package Repair”, con opciones que incluyen “Habilitado”, “Deshabilitado” y “Automático”. Este nuevo modo especial (que es un estándar JEDEC) le permite al fabricante de la memoria aumentar los rendimientos de DRAM al deshabilitar selectivamente las celdas de la memoria defectuosa, para reemplazarlas automáticamente con las que trabajan desde un área de repuesto, Similar a cómo los dispositivos de almacenamiento mapean sectores defectuosos. No estamos seguros de por qué esta característica está siendo expuesta a los usuarios finales, especialmente del segmento de clientes. Tal vez sea eliminado en las placas base de producción.
También hemos encontrado una opción interesante relacionada con el controlador de E / S que le permite seleccionar la generación PCI-Express hasta “Gen 4.0”. Esto podría indicar que algunas placas base de chipset de la serie 400 podrían recibir PCI-Express Gen 4.0, dado que estamos examinando el firmware de una placa base de chipset de la serie 400. Hemos escuchado a través de fuentes creíbles que la implementación PCIe Gen 4.0 de AMD implica el uso de dispositivos de re-controlador externos en la placa base. Estos no son baratos. Texas Instruments vende redrivers Gen 3.0 por $ 1.5 por pieza en cantidades de carretes de 1,000 unidades. Los proveedores de placas base deberán desembolsar al menos $ 15-20 en las placas base AM4 con ranuras Gen 4.0, ya que necesita 20 de estos redrivers, uno por línea. Hemos encontrado varios otros controles comunes, incluyendo “Paridad de RCD”
Una de las páginas del programa de configuración del firmware se titula “SoC Miscellaneous Control” e incluye las siguientes configuraciones, muchas de las cuales son estándares de la industria:
- Reintento de paridad de comando de dirección de DRAM
- Repetición de error de paridad máxima
- Escribir CRC Habilitar
- DRAM escribe CRC Habilitar y reintentar límite
- Max Write CRC Error Replay
- Desactivar la inyección de errores de memoria
- DRAM UECC Reintentar
- Configuraciones ACPI:
o ACPI SRAT L3 Caché como dominio NUMA
o Control de
distancia
ACPI SLIT o Distancia relativa remota ACPI SLIT
o Distancia virtual ACPI SLIT
o ACPI SLIT distancia del zócalo
o ACPI SLIT distancia remota
o ACPI SLIT distancia remota SLink o ACPI SLIT remoto SLink distancia
o ACPI SLIT distancia entre enlaces local
o ACPI SLIT distancia entre enlaces SLL - CLDO_VDDP Control
- Modo de eficiencia
- Control de límite de potencia del paquete
- Estados C del DF
- Estado P de SOC fijo
- CPPC
- Velocidad máxima de 4 enlaces xGMI
- Velocidad máxima de 3 enlaces xGMI
Con todo, AMD Ryzen “Matisse” promete dar a los usuarios avanzados y entusiastas un tesoro de opciones de ajuste. Gracias de nuevo a Yuri “1usmus” Bubliy, quien contribuyó significativamente a este artículo.






{kind=link}